An Electronic Pronouncing Dictionary of Hungarian Words - 2010 (1.5 million word forms)
This is the first open-access electronic pronouncing dictionary of the Hungarian language.
It can be used as a reliable guide to Hungarian pronunciation since its accuracy is over 99%.
Original idea: Gábor Olaszy
Copyright: Budapest University of Technology and Economics, Department of Telecommunications and Media Informatics (BME TMIT), Speech Technology Laboratory (2010).
Implementation: The dictionary is a scientifically sound database whose careful compilation has taken more than four years. Its material consists of 1.5 million lexical items. It presents the orthographic representation of a given word form, accompanied by its pronunciation as represented by a series of phonetic symbols.
Team members and their specific duties: computerised collection of lexical items (Csaba Zainkó), algorithmisation of rules of pronunciation (Géza Kiss, Gábor Olaszy), manual testing of the dictionary (Gábor Olaszy, Klára Laczkó, László Kosztyu, András Béres), program development to help manual testing (Mátyás Bartalis), spell-checking (László Tihanyi, Morphologic), design and programming of computer implementation (Kálmán Abari, University of Debrecen), text-to-sound conversion (Géza Kiss, Gábor Olaszy, Csaba Zainkó, Mátyás Bartalis).
Academic adviser: Péter Siptár (Eötvös Loránd University, Budapest, and Research Institute for Linguistics of the Hungarian Academy of Sciences)
Support: The dictionary is the result of generous and unselfish efforts of the team members listed above. Financial support was not available; technical support was provided by BME TMIT. Many thanks for the expert support of the Language- and Speech Technology Platform (Research Institute for Linguistics, Budapest, Hungary)
The structure and use of the dictionary
Pronouncing dictionaries are useful in research, education, language teaching, various practical applications, and in a host of other areas. By making such electronic dictionaries available via Internet we can widen the range of their applicability even more. As far as we are aware, no public language technology database of this kind has been available so far. Yet the demand for them is large and increasing. We intend to bridge that gap by publishing the present dictionary.
The dictionary contains 1.5 million Hungarian word forms (including both bare stems and suffixed forms). Our exact definition of ‘word form’ is this: a unit in a written text that consists of a series of letters bounded by spaces on both sides. In this respect, the present dictionary differs from traditional dictionaries. Due to this difference, practically any Hungarian word (even in a suffixed form) can be looked up and its pronunciation can be accessed in a written form (as represented in a system chosen by the user) and can even be listened to. The fundamental aim of the dictionary is to present the pronunciation of native Hungarian words (as opposed to foreignisms). The latter can only sporadically be found in the dictionary.
A separate section devoted to the pronunciation of Hungarian family names (many of which have traditional (opaque) spellings) is a further feature of the dictionary that contributes to its usefulness.
Another section on the pronunciation of names of Hungarian settlements includes each and every Hungarian settlement.
For a visual representation of pronunciation, the user can choose among the following three systems:
- Traditional Hungarian transcription (that presents the pronunciation of words in terms of Hungarian letters as if in a completely transparent spelling, e.g., küldte ‘he sent it’ = külte, megkap ‘receive’ = mekkap),
- Symbols of the International Phonetic Alphabet (IPA), e.g., küldte =
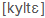 , megkap =
, megkap =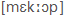 ,
,
- Our internal sound codes used for computational purposes, e.g., küldte = kUlte, megkap = mek:ap)
- SAMPA symbols.
By using IPA symbols, the dictionary presents pronunciations in a form that is intelligible for users of any mother tongue, i.e., it is language-independent. The user is also provided with data concerning the time structure of the pronunciation (durations of segments) for each of the 1.5 million word forms. The durations are given in ms. Long sounds are represented by a colon added to the sound symbol. Interpretation is aided by a sound table in which sound symbols are presented for each letter (for the purposes of search by sound). From the acoustically presented examples of the dictionary, the words can be listened to directly.
The acoustic representations have been implemented by speech technology, that is, typical pronunciations are given in synthesized speech. The rhythm of word forms meets the criteria of Standard Hungarian pronunciation. 55.000 items can be listened to by clicking on the loudspeaker icon.
Search in the dictionary
The dictionary can be searched in two ways: in terms of sound sequences and in terms of letter sequences (spellings).
- In a sound-based search, we can find out which word forms contain the given (sequences of) sounds and what their correct spellings are. This is where the sound table can be used. The desired sound symbols appear as they are clicked on in the table.
- In a letter-based search, we want to find out the correct pronunciation of a word given its spelling, i.e., what sounds are pronounced if the word is uttered. Here, the desired word (letter combination) has to be typed in.
The search space can be widened (narrowed) by the use of special characters. The star (*) has a kind of jolly joker role. For instance, by typing “úszóedző*”, we can access all word forms of the dictionary that are spelt with the sequence of characters preceding the star (úszóedzővel, -nek, -ről, -mnek, -iket, etc.). The character # marks word boundaries. For instance, the sequence #rak gives us a list of words beginning by those characters (raktároz, rakodik, etc.), while rak# leads on to words ending that way (abrak, felrak, bátrak, etc.).
Results of search
The program lists the orthographic and transcribed forms of search results, in terms of the transcription system selected (e.g. IPA).
The search results can be downloaded in the form of tabulated text files (only the first 1000 items of the list of results). This can be done by clicking at the icon  . The structure of the downloadable text files is as follows:
. The structure of the downloadable text files is as follows:
| Column label |
Explanation |
| betűsor ‘Sequence of letters’ |
Written form of the word represented by letters of the Hungarian alphabet |
| hangsor ‘Sequence of sounds’ |
Spoken form of the word represented by symbols of the computer code system |
The following table summarises the correspondences across the four transcription systems:
| Vowels |
| Letter |
Code |
IPA symbol |
SAMPA |
| a |
a |
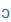 |
O |
| á |
A: |
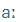 |
a: |
| e |
e |
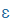 |
E |
| é |
E: |
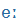 |
e: |
| i |
i |
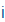 |
i |
| í |
i: |
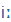 |
i: |
| o |
o |
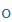 |
o |
| ó |
O |
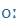 |
o: |
| ö |
o: |
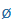 |
2 |
| ő |
O: |
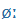 |
2: |
| u |
u |
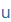 |
u |
| ú |
U |
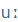 |
u: |
| ü |
u: |
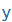 |
y |
| ű |
U: |
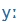 |
y: |
|
| Consonants |
| Letter |
Code |
IPA symbol |
SAMPA |
| b |
b |
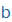 |
b |
| p |
p |
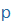 |
p |
| d |
d |
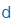 |
d |
| t |
t |
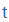 |
t |
| gy |
G |
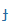 |
d' |
| ty |
T |
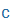 |
t' |
| g |
g |
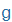 |
g |
| k |
k |
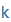 |
k |
| m |
m |
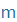 |
m |
| n |
n |
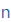 |
n |
| ny |
N |
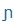 |
J |
| j, ly |
j |
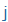 |
j |
| h |
h |
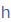 |
h |
| v |
v |
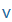 |
v |
| f |
f |
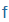 |
f |
| z |
z |
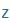 |
z |
| sz |
s |
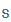 |
s |
| dz |
dz |
 |
dz |
| c |
c |
 |
ts |
| zs |
Z |
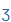 |
Z |
| s |
S |
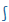 |
S |
| dzs |
dZ |
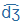 |
dZ |
| cs |
C |
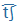 |
tS |
| l |
l |
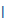 |
l |
| r |
r |
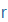 |
r |
|
| Allophones |
| Code |
IPA symbol |
SAMPA |
Example |
| j+ |
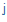 |
j |
fia |
| J |
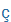 |
x' |
lépj |
| H |
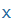 |
x |
doh |
| CH |
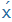 |
x |
pech |
| n+ |
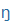 |
N |
ing |
| n' |
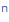 |
n |
unsz |
|
Legend:
| · |
j+ |
A brief [j]-like transition between two adjacent vowels, for hiatus resolution |
| · |
J |
Voiceless palatal fricative, as in lépj ‘step-imperative’ |
| · |
H |
Voiceless velar fricative, as in doh ‘musty smell’ |
| · |
CH |
Voiceless prevelar fricative, as in pech ‘bad luck’ |
| · |
n+ |
Velar nasal, a variant of [n] occurring before [k], [g] |
| · |
n’ |
Nasalisation: the dentialveolar closure of [n] is not formed but the preceding vowel is nasalised and lengthened in compensation |
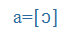
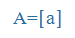
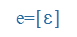
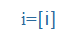
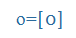
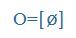
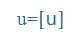
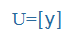
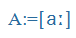
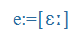
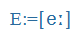
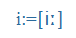
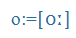
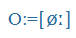
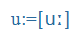
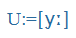
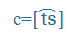
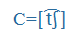
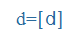
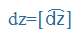

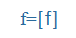
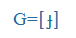
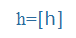
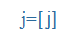
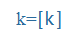
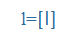
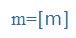
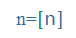
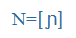
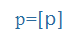
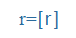
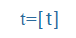
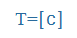
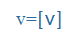
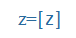
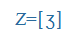
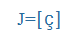
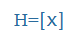
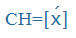
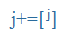
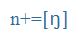
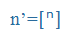
 Magyar
Magyar