Magyar szavak elektronikus kiejtési szótára - 2010 (1,5 millió szóalak)
Ez az első nyilvános, elektronikus kiejtési szótár a magyar nyelvre.
Referenciaként használható, mivel pontossága 99% feletti.
Alapgondolat: Olaszy Gábor
Copyright: Budapesti Műszaki és Gazdaságtudományi Egyetem Távközlési és Médiainformatikai Tanszék (BME TMIT), Beszédtechnológiai Laboratórium (2010).
Megvalósítás: A szótár négy évig készült, tudományos igényességgel megvalósított adattár. Nyelvi anyaga 1,5 millió lexikai egységből áll. Megadja a szóalak ortografikus formáját, mellette pedig a kiejtést hangjelek sorozatával.
Az alapgondolatot megvalósító csapat és tevékenysége: a lexikai egységek számítógépes gyűjtése (Zainkó Csaba), a kiejtési szabályok algoritmizálása (Kiss Géza, Olaszy Gábor), a szótár manuális tesztelése (Olaszy Gábor, Laczkó Klára, Kosztyu László, Béres András), a manuális tesztelés segítésére programfejlesztés (Bartalis Mátyás), helyesírás-ellenőrzés (Tihanyi László*), az internetes megvalósítás tervezése, programozása (Abari Kálmán**), a szótár hangosítása (Kiss Géza, Olaszy Gábor, Zainkó Csaba, Bartalis Mátyás).
* Morphologic, ** Debreceni Egyetem
Lektor és tudományos tanácsadó: Siptár Péter (MTA Nyelvtudományi Intézet)
Támogatás: A szótár a fenti munkatársak áldozatos munkájának eredménye. A fejlesztéshez pénztámogatást nem kaptunk. A műszaki hátteret a BME TMIT szolgáltatta. A szakmai tanácsokat köszönjük a Nyelv- és Beszédtechnológiai Platformnak (MTA Nyelvtudományi Intézet).
A szótár felépítése, használata
A kiejtési szótárak jól használhatók a kutatásban, az oktatásban, a nyelvtanításban, számos gyakorlati alkalmazásban és még sok más területen. Az ilyen elektronikus szótárak Interneten való közreadása tovább tágítja a használat terét. Tudomásunk szerint magyar nyelvre, ilyen nyilvánosan hozzáférhető nyelvtechnológiai adattár eddig nem állt rendelkezésre az Interneten. Az igény viszont világszerte nagy. Ezt a hiányt kívánjuk pótolni a jelen szótár közreadásával.
A szótár 1,5 millió magyar szóalakot tartalmaz (szavak toldalékolatlan és toldalékolt formáit egyaránt). A szóalak pontos definíciója a következő: olyan lexikai egység egy szövegben, amely két szóköz közötti betűkarakterek sorozata. Ilyen tekintetben ez a szótár más szerkezetű, mint a hagyományos szótárak. Ebből a szerkezeti felépítésből adódik, hogy szinte bármilyen magyar szó (akár toldalékolt, ragozott formában is) kereshető, és a kiejtése megkapható írott formában (választható hangreprezentációkkal), illetve hangos formában meg is hallgatható. A szótár alapvető célja a magyar szavak kiejtésének megadása (nem idegen szavaké). Idegen szó csak elvétve található a szótárban.
A magyar családnevek kiejtését tartalmazó blokk tovább szélesíti a szótár használati lehetőségeit .
A magyar települések neveinek kiejtését tartalmazó blokk tartalmazza az összes magyar települést.
A kiejtés írott formában történő megadására három forma választható:
- hagyományos magyar átírás (magyar betűkkel adja meg a kiejtést, például: küldte=külte, megkap=mekkap)
- nemzetközi fonetikai (IPA) szimbólumok, például: küldte=
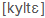 , megkap=
, megkap=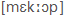 ,
,
- belső számítógépes hangkód jelölés, például: küldte= kUlte, megkap = mek:ap)
- SAMPA jelölés.
Az IPA hangszimbólumok segítségével a szótár használata bármely anyanyelvű személy részére egyértelmű kiejtést ad meg, tehát nyelvfüggetlen. A kiejtés időszerkezeti adatait (hangidőtartamok) is megkapja a használó mind az 1,5 millió szóalakra. A megmutatott hangidőtartamok ms-ban szerepelnek. A hosszú hangokat kettőspont melléírásával jelöljük. Az értelmezést segíti a hangtáblázat, amelyben a betűképnek megfelelő hangok megtekinthetők (hang szerinti keresésnél). A szótár hangos részének példáiból a kiejtés akusztikai formáját lehet meghallgatni.
A hangos szótár részt beszédtechnológiai eszközökkel valósítottuk meg, szintetizált beszéddel adjuk meg a jellemző kiejtést. A szóalakok kiejtési ritmusa megfelel a magyar köznyelvi kiejtés kritériumainak. A szótárból 55 000 elem meghallgatható, ha a hangszóróra kattintunk.
Keresés a szótárban
Kétféle módon kereshetünk a szótárban: hang alapján vagy betű alapján.
- beszédhang alapú lekérdezésnél arra vagyunk kíváncsiak, hogy a megadott hang(csoport) milyen szóban fordul elő és annak milyen a helyesírás szerinti képe. A hangmegadáshoz segít a hangtáblázat. Rákattintással megjelennek a használható hangjelek, amelyek közül kattintással kiválaszthatjuk a kívánt hangokat.
- betű alapú lekérdezésnél arra vagyunk kíváncsiak, hogy a helyesírás szerint megadott szónak milyen a kiejtése, milyen hangokat ejtünk a kimondásakor. Ilyenkor szót (esetleg betűkapcsolatot) célszerű megadni.
Speciális karakterek használata tágítja (szűkíti) a keresés terét. A * karakter egyfajta dzsókerszerepet tölt be a keresés megadásában. Például az „úszóedző*” megadásakor a szótár minden olyan szót megmutat, amely a * előtti karaktersorozattal íródik (úszóedzővel, -nek, -ről, -mnek, -iket stb.). A # karakter szókezdetet, illetve befejezést jelöl. Például a #rak betűsorozat megadására csak az ilyen kezdetű szavak jelennek meg a listában (raktároz, rakodik, stb), a rak# betűsorozatra csak az ilyen végűek (abrak, felrak, bátrak stb.).
A lekérdezés eredménye
A program a találatok szöveges és hangátírásos formáját a kiválasztott hangábrázolási forma szerint (például IPA jelekkel) listázza ki egymás alatt.
A lekérdezés eredményét elmenthetjük tabulátorral tagolt szöveges állományba is. A találati lista első 1000 elemét tölthetjük le. A tabulátorral tagolt állomány létrehozását a  ikonra kattintva kérhetjük. A letölthető szöveges állomány szerkezete a következő:
ikonra kattintva kérhetjük. A letölthető szöveges állomány szerkezete a következő:
| Oszlopnév |
Magyarázat |
| betűsor |
a szó írott alakja a magyar ábécé betűivel |
| hangsor |
a szó ejtett alakja számítógépes hangjelöléssel |
A négy átírási forma kapcsolatát a következő táblázat mutatja:
| Magánhangzók |
| Betű |
Hangkód |
IPA-jel |
SAMPA |
| a |
a |
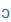 |
O |
| á |
A: |
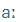 |
a: |
| e |
e |
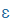 |
E |
| é |
E: |
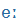 |
e: |
| i |
i |
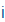 |
i |
| í |
i: |
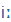 |
i: |
| o |
o |
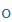 |
o |
| ó |
O |
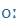 |
o: |
| ö |
o: |
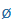 |
2 |
| ő |
O: |
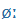 |
2: |
| u |
u |
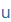 |
u |
| ú |
U |
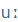 |
u: |
| ü |
u: |
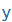 |
y |
| ű |
U: |
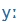 |
y: |
|
| Mássalhangzók |
| Betű |
Hangkód |
IPA-jel |
SAMPA |
| b |
b |
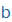 |
b |
| p |
p |
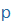 |
p |
| d |
d |
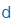 |
d |
| t |
t |
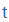 |
t |
| gy |
G |
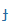 |
d' |
| ty |
T |
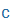 |
t' |
| g |
g |
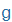 |
g |
| k |
k |
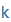 |
k |
| m |
m |
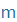 |
m |
| n |
n |
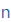 |
n |
| ny |
N |
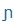 |
J |
| j, ly |
j |
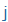 |
j |
| h |
h |
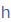 |
h |
| v |
v |
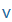 |
v |
| f |
f |
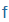 |
f |
| z |
z |
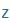 |
z |
| sz |
s |
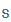 |
s |
| dz |
dz |
 |
dz |
| c |
c |
 |
ts |
| zs |
Z |
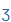 |
Z |
| s |
S |
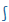 |
S |
| dzs |
dZ |
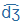 |
dZ |
| cs |
C |
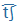 |
tS |
| l |
l |
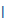 |
l |
| r |
r |
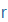 |
r |
|
| Allofónok |
| Hangkód |
IPA-jel |
SAMPA |
Példa |
| j+ |
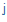 |
j |
fia |
| J |
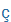 |
x' |
lépj |
| H |
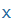 |
x |
doh |
| CH |
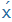 |
x |
pech |
| n+ |
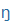 |
N |
ing |
| n' |
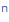 |
n |
unsz |
|
Magyarázat:
| · |
j+ |
hiátustöltő, rövid [j]-szerű hang két magánhangzó között |
| · |
J |
zöngétlen palatális réshang, például a lépj szó végén |
| · |
H |
zöngétlen veláris réshang, például a doh szó végén |
| · |
CH |
zöngétlen preveláris réshang, például a pech szó végén |
| · |
n+ |
veláris nazális, az [n] variánsa a [k], [g] hangok előtt |
| · |
n’ |
nazalizációt jelent: nem valósul meg az [n] dentialveoláris artikulációja, a megelőző magánhangzó viszont nazalizálódik. |
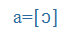
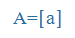
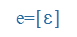
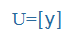
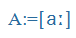
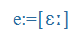
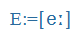
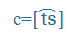
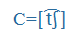
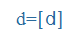
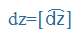

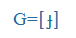
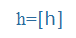
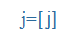
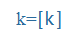
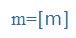
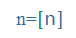
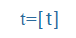
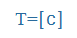
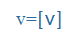
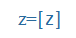
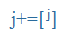
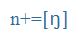
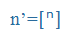
 English
English